DataFu's Hourglass, Incremental Data Processing in Hadoop
Matthew Hayes
For a large scale site such as LinkedIn, tracking metrics accurately and efficiently is an important task. For example, imagine we need a dashboard that shows the number of visitors to every page on the site over the last thirty days. To keep this dashboard up to date, we can schedule a query that runs daily and gathers the stats for the last 30 days. However, this simple implementation would be wasteful: only one day of data has changed, but we'd be consuming and recalculating the stats for all 30.
A more efficient solution is to make the query incremental: using basic arithmetic, we can update the output from the previous day by adding and subtracting input data. This enables the job to process only the new data, significantly reducing the computational resources required. Unfortunately, although there are many benefits to the incremental approach, getting incremental jobs right is hard:
- The job must maintain state to keep track of what has already been done, and compare this against the input to determine what to process.
- If the previous output is reused, then the job needs to be written to consume not just new input data, but also previous outputs.
- There are more things that can go wrong with an incremental job, so you typically need to spend more time writing automated tests to make sure things are working.
To solve these problems, we are happy to announce that we have open sourced Hourglass, a framework that makes it much easier to write incremental Hadoop jobs. We are releasing Hourglass under the Apache 2.0 License as part of the DataFu project. We will be presenting our "Hourglass: a Library for Incremental Processing on Hadoop" paper at the IEEE BigData 2013 conference on October 9th.
In this post, we will give an overview of the basic concepts behind Hourglass and walk through examples of using the framework to solve processing tasks incrementally. The first example presents a job that counts how many times a member has logged in to a site. The second example presents a job that estimates the number of members who have visited in the past thirty days. Lastly, we will show you how to get the code and start writing your own incremental hadoop jobs.
Basic Concepts
Hourglass is designed to make computations over sliding windows more efficient. For these types of computations, the input data is partitioned in some way, usually according to time, and the range of input data to process is adjusted as new data arrives. Hourglass works with input data that is partitioned by day, as this is a common scheme for partitioning temporal data.
We have found that two types of sliding window computations are extremely common in practice:
- Fixed-length: the length of the window is set to some constant number of days and the entire window moves forward as new data becomes available. Example: a daily report summarizing the the number of visitors to a site from the past 30 days.
- Fixed-start: the beginning of the window stays constant, but the end slides forward as new input data becomes available. Example: a daily report summarizing all visitors to a site since the site launched.
We designed Hourglass with these two use cases in mind. Our goal was to design building blocks that could efficiently solve these problems while maintaining a programming model familiar to developers of MapReduce jobs.
The two major building blocks of incremental processing with Hourglass are a pair of Hadoop jobs:
- Partition-preserving: consumes partitioned input data and produces partitioned output.
- Partition-collapsing: consumes partitioned input data and merges it to produce a single output.
We'll discuss these two jobs in the next two sections.
Partition-preserving job
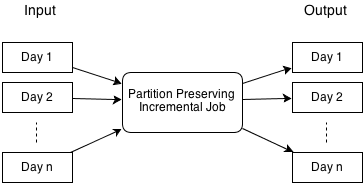
In the partition-preserving job, input data that is partitioned by day is consumed and output data is produced that is also partitioned by day. This is equivalent to running one MapReduce job separately for each day of input data. Suppose that the input data is a page view event and the goal is to count the number of page views by member. This job would produce the page view counts per member, partitioned by day.
Partition-collapsing job
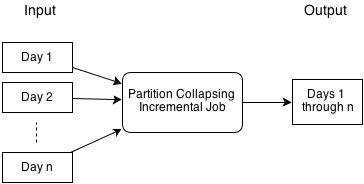
In the partition-collapsing job, input data that is partitioned by day is consumed and a single output is produced. If the input data is a page view event and the goal is to count the number of page views by member, then this job would produce the page view counts per member over the entire n days.
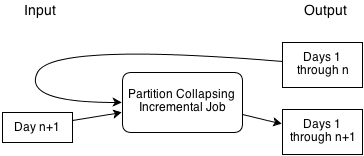
Functionally, the partition-collapsing job is not too different from a standard MapReduce job. However, one very useful feature it has is the ability to reuse its previous output, enabling it to avoid reprocessing input data. So if day n+1 arrives, it can merge it with the previous output, without having to reprocess days 1 through n. For many aggregation problems, this makes the computation much more efficient.
Hourglass programming model
The Hourglass jobs are implemented as MapReduce jobs for Hadoop:
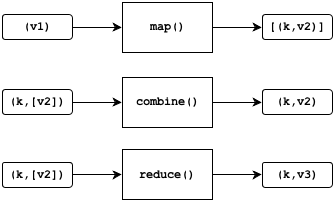
The map method receives values from the input data and, for each input, produces zero or more key-value pairs as output. Implementing the map operation is similar to implementing the same for Hadoop, just with a different interface. For the partition-preserving job, Hourglass automatically keeps the data partitioned by day, so the developer can focus purely on the application logic.
The reduce method receives each key and a list of values. For each key, it produces the same key and a single new value. In some cases, it could produce no output at all for a particular key. In a standard reduce implementation in Hadoop, the programmer is provided an interface to the list of values and is responsible for pulling each value from it. With an accumulator, this is reversed: the values are passed in one at a time and at most one value can be produced as output.
The combine method is optional and can be used as an optimization. Its purpose is to reduce the amount of data that is passed to the reducer, limiting I/O costs. Like the reducer, it also uses an accumulator. For each key, it produces the same key and a single new value, where the input and output values have the same type.
Hourglass uses Avro for all of the input and output data types in the diagram above, namely k, v, v2, and v3. One of the tasks when programming with Hourglass is to define the schemas for these types. The exception is the input schema, which is implicitly determined by the jobs when the input is inspected.
Example 1: Counting Events Per Member
With the basic concepts out of the way, let's look at an example. Suppose that we have a website that tracks user logins as an event, and for each event, the member ID is recorded. These events are collected and stored in HDFS in Avro under paths with the format /data/event/yyyy/MM/dd. Suppose for this example our Avro schema is:
{
"type" : "record", "name" : "ExampleEvent",
"namespace" : "datafu.hourglass.test",
"fields" : [ {
"name" : "id",
"type" : "long",
"doc" : "ID"
} ]
}
The goal is to count how many times each member has logged in over the entire history and produce a daily report containing these counts. One solution is to simply consume all data under /data/event each day and aggregate by member ID. While this solution works, it is very wasteful (and only gets more wasteful over time), as it recomputes all the data every day, even though only 1 day worth of data has changed. Wouldn't it be better if we could merge the previous result with the new data? With Hourglass you can.
To continue our example, let's say there are two days of data currently available, 2013/03/15 and 2013/03/16, and that their contents are:
2013/03/15:
{"id": 1}, {"id": 1}, {"id": 1}, {"id": 2}, {"id": 3}, {"id": 3}
2013/03/16:
{"id": 1}, {"id": 1}, {"id": 2}, {"id": 2}, {"id": 3},
Let's aggregate the counts by member ID using Hourglass. To perform the aggregation we will use PartitionCollapsingIncrementalJob, which takes a partitioned data set and collapses all the partitions together into a single output. The goal is to aggregate the two days of input and produce a single day of output, as in the following diagram:

First, create the job:
PartitionCollapsingIncrementalJob job =
new PartitionCollapsingIncrementalJob(Example.class);
Next, we will define schemas for the key and value used by the job. The key affects how data is grouped in the reducer when we perform the aggregation. In this case, it will be the member ID. The value is the piece of data being aggregated, which will be an integer representing the count.
final String namespace = "com.example";
final Schema keySchema =
Schema.createRecord("Key",null,namespace,false);
keySchema.setFields(Arrays.asList(
new Field("member_id",Schema.create(Type.LONG),null,null)));
final String keySchemaString = keySchema.toString(true);
final Schema valueSchema =
Schema.createRecord("Value",null,namespace,false);
valueSchema.setFields(Arrays.asList(
new Field("count",Schema.create(Type.INT),null,null)));
final String valueSchemaString = valueSchema.toString(true);
This produces the following representation:
{
"type" : "record", "name" : "Key", "namespace" : "com.example",
"fields" : [ {
"name" : "member_id",
"type" : "long"
} ]
}
{
"type" : "record", "name" : "Value", "namespace" : "com.example",
"fields" : [ {
"name" : "count",
"type" : "int"
} ]
}
Now we can tell the job what our schemas are. Hourglass allows two different value types. One is the intermediate value type that is produced by the mapper and combiner. The other is the output value type, the product of the reducer. In this case we will use the same value type for each.
job.setKeySchema(keySchema);
job.setIntermediateValueSchema(valueSchema);
job.setOutputValueSchema(valueSchema);
Next, we will tell Hourglass where to find the data, where to write the data, and that we want to reuse the previous output.
job.setInputPaths(Arrays.asList(new Path("/data/event")));
job.setOutputPath(new Path("/output"));
job.setReusePreviousOutput(true);
Now let's get into some application logic. The mapper will produce a key-value pair from each input record, consisting of the member ID and a count, which for each input record will just be 1.
job.setMapper(new Mapper<GenericRecord,GenericRecord,GenericRecord>()
{
private transient Schema kSchema;
private transient Schema vSchema;
@Override
public void map(
GenericRecord input,
KeyValueCollector<GenericRecord, GenericRecord> collector)
throws IOException, InterruptedException
{
if (kSchema == null)
kSchema = new Schema.Parser().parse(keySchemaString);
if (vSchema == null)
vSchema = new Schema.Parser().parse(valueSchemaString);
GenericRecord key = new GenericData.Record(kSchema);
key.put("member_id", input.get("id"));
GenericRecord value = new GenericData.Record(vSchema);
value.put("count", 1);
collector.collect(key,value);
}
});
An accumulator is responsible for aggregating this data. Records will be grouped by member ID and then passed to the accumulator one-by-one. The accumulator keeps a running total and adds each input count to it. When all data has been passed to it, the getFinal() method will be called, which returns the output record containing the count.
job.setReducerAccumulator(new Accumulator<GenericRecord,GenericRecord>()
{
private transient int count;
private transient Schema vSchema;
@Override
public void accumulate(GenericRecord value) {
this.count += (Integer)value.get("count");
}
@Override
public GenericRecord getFinal() {
if (vSchema == null)
vSchema = new Schema.Parser().parse(valueSchemaString);
GenericRecord output = new GenericData.Record(vSchema);
output.put("count", count);
return output;
}
@Override
public void cleanup() {
this.count = 0;
}
});
Since the intermediate and output values have the same schema, the accumulator can also be used for the combiner, so let's indicate that we want it to be used for that:
job.setCombinerAccumulator(job.getReducerAccumulator());
job.setUseCombiner(true);
Finally, we run the job.
job.run();
When we inspect the output we find that the counts match what we expect:
{"key": {"member_id": 1}, "value": {"count": 5}}
{"key": {"member_id": 2}, "value": {"count": 3}}
{"key": {"member_id": 3}, "value": {"count": 3}}
Now suppose that a new day of data becomes available:
2013/03/17:
{"id": 1}, {"id": 1}, {"id": 2}, {"id": 2}, {"id": 2},
{"id": 3}, {"id": 3}
Let's run the job again. Since Hourglass already has a result for the previous day, it consumes the new day of input and the previous output, rather than all the input data it already processed.
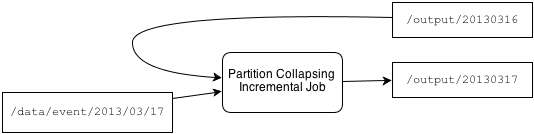
The previous output is passed to the accumulator, where it is aggregated with the new data. This produces the output we expect:
{"key": {"member_id": 1}, "value": {"count": 7}}
{"key": {"member_id": 2}, "value": {"count": 6}}
{"key": {"member_id": 3}, "value": {"count": 5}}
In this example, we only have a few days of input data, so the impact of incrementally processing the new data is small. However, as the size of the input data grows, the benefit of incrementally processing data becomes very significant.
Example 2: Cardinality Estimation
Suppose that we have another event that tracks every page view that occurs on the site. One piece of information recorded in the event is the member ID. We want to use this event to tackle another problem: a daily report that estimates the number of members who are active on the site in the past 30 days.
The straightforward approach is to read in the past 30 days of data, perform a distinct operation on the member IDs, and then count the IDs. However, as in the previous case, the input data day-to-day is practically the same. It only differs in the days at the beginning and end of the window. This means that each day we are repeating much of the same work. But unlike the previous case, we cannot simply merge in the new day of data with the previous output because the window length is fixed and we want the oldest day to be removed when the window advances. The PartitionCollapsingIncrementalJob class alone from the previous example will not solve this problem.
Hourglass includes another class to address the fixed-length sliding window use case: the PartitionPreservingIncrementalJob. This type of job consumes partitioned input data, just like the collapsing version, but unlike the other job its output is partitioned. It keeps the data partitioned as it is processing it and uses Hadoop's multiple-outputs feature to produce data partitioned by day. This is equivalent to running a MapReduce job for each individual day of input data, but much more efficient.
With the PartitionPreservingIncrementalJob, we can perform aggregation per day and then use the PartitionCollapsingIncrementalJob to produce the final result. For basic arithmetic-based operations like summation, we could even save ourselves more work by reusing the output, subtracting off the oldest day and adding the newest one.
So how can we use the two jobs together to get the cardinality of active members over the past 30 days? One solution is to use PartitionPreservingIncrementalJob to produce daily sets of distinct member IDs. That is, each day of data produced has all the IDs for members that accessed the site that day. In other words, this is a distinct operation. Then PartitionCollapsingIncrementalJob can consume this data, perform distinct again, and count the number of IDs. The benefit of this approach is that when a new day of data arrives, the partition-preserving job only needs to process that new day and nothing else, as the previous days have already been processed. This idea is outlined below.
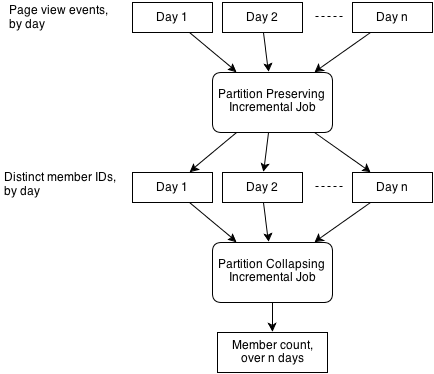
This solution should be more efficient than the naive solution. However, if an estimation of member cardinality is satisfactory, then we could make the job even more efficient. HyperLogLog is capable of estimating the cardinality of large data sets very accurately using a relatively small amount of memory. For example, cardinalities in the billions can be estimated to within 2% accuracy using only 1.5kb of memory. It's also friendly to distributed computing as multiple HyperLogLog estimators can be merged together.
HyperLogLog is a good fit for this use case. For this example, we will use HyperLogLogPlus from stream-lib, an implementation based on this paper that includes some enhancements to the original algorithm. We can use a HyperLogLogPlus estimator for each day of input data in the partition-preserving job and serialize the estimator's bytes as the output. Then the partition-collapsing job can merge together the estimators for the time window to produce the final estimate.
Let's start by defining the mapper. The key it uses is just a dummy value, as we are only producing a single statistic in this case. For the value we use a record with two fields: one is the count estimate; the other we'll just call "data", which can be either a single member ID or the bytes from the serialized estimator. For the map output we use the member ID.
Mapper<GenericRecord,GenericRecord,GenericRecord> mapper =
new Mapper<GenericRecord,GenericRecord,GenericRecord>() {
private transient Schema kSchema;
private transient Schema vSchema;
@Override
public void map(
GenericRecord input,
KeyValueCollector<GenericRecord, GenericRecord> collector)
throws IOException, InterruptedException
{
if (kSchema == null)
kSchema = new Schema.Parser().parse(keySchemaString);
if (vSchema == null)
vSchema = new Schema.Parser().parse(valueSchemaString);
GenericRecord key = new GenericData.Record(kSchema);
key.put("name", "member_count");
GenericRecord value = new GenericData.Record(vSchema);
value.put("data",input.get("id")); // member id
value.put("count", 1L); // just a single member
collector.collect(key,value);
}
};
Next, we'll define the accumulator, which can be used for both the combiner and the reducer. This accumulator can handle either member IDs or estimator bytes. When it receives a member ID it adds it to the HyperLogLog estimator. When it receives an estimator it merges it with the current estimator to produce a new one. To produce the final result, it gets the current estimate and also serializes the current estimator as a sequence of bytes.
Accumulator<GenericRecord,GenericRecord> accumulator =
new Accumulator<GenericRecord,GenericRecord>() {
private transient HyperLogLogPlus estimator;
private transient Schema vSchema;
@Override
public void accumulate(GenericRecord value)
{
if (estimator == null) estimator = new HyperLogLogPlus(20);
Object data = value.get("data");
if (data instanceof Long)
{
estimator.offer(data);
}
else if (data instanceof ByteBuffer)
{
ByteBuffer bytes = (ByteBuffer)data;
HyperLogLogPlus newEstimator;
try
{
newEstimator =
HyperLogLogPlus.Builder.build(bytes.array());
estimator =
(HyperLogLogPlus)estimator.merge(newEstimator);
}
catch (IOException e)
{
throw new RuntimeException(e);
}
catch (CardinalityMergeException e)
{
throw new RuntimeException(e);
}
}
}
@Override
public GenericRecord getFinal()
{
if (vSchema == null)
vSchema = new Schema.Parser().parse(valueSchemaString);
GenericRecord output = new GenericData.Record(vSchema);
try
{
ByteBuffer bytes =
ByteBuffer.wrap(estimator.getBytes());
output.put("data", bytes);
output.put("count", estimator.cardinality());
}
catch (IOException e)
{
throw new RuntimeException(e);
}
return output;
}
@Override
public void cleanup()
{
estimator = null;
}
};
So there you have it. With the mapper and accumulator now defined, it is just a matter of passing them to the jobs and providing some other configuration. The key piece is to ensure that the second job uses a 30 day sliding window:
PartitionCollapsingIncrementalJob job2 =
new PartitionCollapsingIncrementalJob(Example.class);
// ...
job2.setNumDays(30); // 30 day sliding window
Try it yourself!
Update (10/15/2015): Please see the updated version of these instructions at Getting Started, which have changed significantly. The instructions below will not work with the current code base, which has moved to Apache.
Here is how you can start using Hourglass. We'll test out the job from the first example against some test data we'll create in a Hadoop. First, clone the DataFu repository and navigate to the Hourglass directory:
git clone https://github.com/linkedin/datafu.git
cd contrib/hourglass
Build the Hourglass JAR, and in addition build a test jar that contains the example jobs above.
ant jar
ant testjar
Define some variables that we'll need for the hadoop jar command. These list the JAR dependencies, as well as the two JARs we just built.
export LIBJARS=$(find "lib/common" -name '*.jar' | xargs echo | tr ' ' ',')
export LIBJARS=$LIBJARS,$(find "build" -name '*.jar' | xargs echo | tr ' ' ',')
export HADOOP_CLASSPATH=`echo ${LIBJARS} | sed s/,/:/g`
Generate some test data under /data/event using a generate tool. This will create some random events for dates between 2013/03/01 and 2013/03/14. Each record consists of just a single long value in the range 1-100.
hadoop jar build/datafu-hourglass-test.jar generate -libjars ${LIBJARS} /data/event 2013/03/01-2013/03/14
Just to get a sense for what the data looks like, we can copy it locally and dump the first several records.
hadoop fs -copyToLocal /data/event/2013/03/01/part-00000.avro temp.avro
java -jar lib/test/avro-tools-jar-1.7.4.jar tojson temp.avro | head
Now run the countbyid tool, which executes the job from the first example that we defined earlier. This will count the number of events for each ID value. In the output you will notice that it reads all fourteen days of input that are available.
hadoop jar build/datafu-hourglass-test.jar countbyid -libjars ${LIBJARS} /data/event /output
We can see what this produced by copying the output locally and dumping the first several records. Each record consists of an ID and a count.
rm temp.avro
hadoop fs -copyToLocal /output/20130314/part-r-00000.avro temp.avro
java -jar lib/test/avro-tools-jar-1.7.4.jar tojson temp.avro | head
Now let's generate an additional day of data for 2013/03/15.
hadoop jar build/datafu-hourglass-test.jar generate -libjars ${LIBJARS} /data/event 2013/03/15
We can run the incremental job again. This time it will reuse the previous output and will only consume the new day of input.
hadoop jar build/datafu-hourglass-test.jar countbyid -libjars ${LIBJARS} /data/event /output
We can download the new output and inspect the counts:
rm temp.avro
hadoop fs -copyToLocal /output/20130315/part-r-00000.avro temp.avro
java -jar lib/test/avro-tools-jar-1.7.4.jar tojson temp.avro | head
Both of the examples in this post are also included as unit tests in the Example class within the source code. Some code has been omitted from the examples in this post for sake of space, so please check the original source if you're interested in more of the details.
If you're interested in the project, we also encourage you to try running the unit tests, which can be run in Eclipse once the project is loaded there, or by running ant test at the command line.
Conclusion
We hope this whets your appetite for incremental data processing with DataFu's Hourglass. The code is available on Github in the DataFu repository under an Apache 2.0 license. Documentation is available here. We are accepting contributions, so if you are interesting in helping out, please fork the code and send us your pull requests!
Update (10/15/2015): The links in this blog post have been updated to point to the correct locations within the Apache DataFu website.
